

NFL Elo Power Rankings for 2025

Once again, it's time for the annual NFL Elo update! I've completed my biggest model search yet, resulting in a more historically accurate model. Last year's model search used historic games going back to 2010, but this year's goes back to 1992. See "The Search" below for more details.
The new 2025 season ratings and rankings page is now live! Previous season pages, starting with 2024, have been updated to show ratings and rankings calculated with the new model.
The season pages using last year's model are now available as a new set of "frozen" pages that show the ratings and rankings as they appeared immediately following the Super Bowl in February 2025:
- Regular model "frozen February 2025" pages: 2024, 2023, 2022, 2021, 2020
- "Blank Slate" model "frozen February 2025" pages: 2024, 2023, 2022, 2021, 2020
- "Never Lose Elo For a Win" model "frozen February 2025" pages: 2024, 2023, 2022, 2021, 2020
- "No Margin of Victory" model "frozen February 2025" pages: 2024, 2023, 2022, 2021, 2020
For the 2025 season, I am ending the experiments with the "Never Lose Elo For a Win" and "No Margin of Victory" models. While interesting to look at, they are less accurate than the "regular" model and just create a lot of complication for me and likely cause confusion for readers. I'll continue to evaluate experimental model changes, and as always will publish ratings and rankings using whatever model is most accurate.
Elo model Background
For background on why and how I apply Elo ratings to NFL teams, see last year's post.
Comparing Models
Like last year, Elo models were compared using a "score" value, where higher scores are better:
where:
- "winners" — the number of correctly-picked game winners
- "stddev" — the standard deviation of the percentage of correctly-picked game winners across seasons
- the idea is to decrease the score of models that have more variation from one season to the next, so as to penalize overfitting
The 5.5 value is subjective, but appeared to create a nice balance between accuracy and consistency from one season to the next.
I calculated the scores with weighting to place more weight on more recent seasons. Due to rule changes over the years, there are likely differences between how, for example, a 14-point margin of victory on the road "should" be rewarded for the 2024 season vs. the 1994 season. Since whatever difference that might be from season to season is unknowable, I gradually decreased the weight of historic seasons. The score in the table below reflects weighted winners and weighted "stddev" from 1992-2024, where 1992 and 1993 were "warmup" (uncounted) seasons and where 2004-2024 are fully weighted. Before 2004, seasons decrease in weight linearly until 1995 and earlier, which have a 10% weight.
The Search
For each model "type" in the table below, I ran a search of 10 million random models. I experimented with Optuna to find models using an algorithmic approach, but I found it never was able to match the accuracy of the best models found with pure brute force: completely random models. I did end up using Optuna to replace my custom "fine tune" procedure performed on the random models. In the end, I found using models generated with random parameters, then "fine-tuned" with Optuna, gave the best results.
To further refine the best found random models, I took a handful of the best random models and performed a "merge" for each pair among them. When "merging" a pair of models, every possible combination of their parameters was tested (after being "fine tuned" with Optuna) as a child "generation 2" model. Child models were only kept if they were better than both parents, and this was repeated for each generation. The single best "Never Lose Elo For a Win" model ended up being a generation 6 model, and the best "regular" model was generation 5. I did a similar "genetic refinement" process in last offseason's model search, but the child models weren't fully "fine tuned" like this year.
In my first automated model search from last year, I examined random models over 12 fully-weighted seasons from 2012-2023. I'm not sure how many models were examined, but I believe it was somewhere between a few hundred thousand and a million. To reduce the chance of finding an outlier overfitted model (that could perform poorly in the upcoming season) I increased the number of evaluated seasons from 12 to 21, plus an additional 10 seasons at a reduced weight.
After examining 10 million models for each of the two model "types" below, the one listed in the top row of
the table below, as expected, turned out to have the best accuracy. That model, which I'll call v3.2025.06
is being used for the 2025 season.
Model "Types"
As of the end of August 2025, I haven't completed the model search for all model types but I have completed the big searches for the regular, "never lose Elo for a win," and "blank slate" models. Running the randomized search for each model type takes my computer several weeks, and then the merge process takes another few days longer. And it turns my computer into a little space heater! I may run more model searches later this fall once my office gets a bit chilly.
The columns below show features that are switched on and off for the different model types:
- "division adj" — find and apply a factor to penalize strong teams less for "worse than expected" performance against division opponents (and vice versa)
- "seed lock adj" — find and apply a factor to penalize teams less for losing "meaningless" games at the end of the season
- "winpos" — never lose Elo rating points for a win: teams lose no Elo rating points after beating a weaker team by a smaller than expected margin
- "no MOV" — margin of victory is not involved in Elo rating points exchange
- "blank slate" — all teams begin every season with the same Elo rating
Scores by Model Type, 1992-2024
| weighted score = winners - (stddev*5.5) | division adj | seed lock adj | winpos | no MOV | blank slate | notes |
|---|---|---|---|---|---|---|
| 4527.46 = 4543.95 - (3.00x5.5) | ✓ | ✓ | The "regular" model. As expected, so far this is the best model type and became the new "v3.2025.06". | |||
| 4512.71 = 4529.82 - (3.11x5.5) | ✓ | ✓ | ✓ | This is the "never lose Elo for a win" model. Surprisingly, only slightly less accurate than the regular model. | ||
| ✓ | ✓ | ✓ | ||||
| 4420.41 = 4436.65 - (2.95x5.5) | ✓ | ✓ | ✓ | Better than 2024's "blank slate" model, and worse than the regular, as expected. | ||
| ✓ | ✓ | ✓ | ✓ | |||
| ✓ | ✓ | ✓ | ✓ | |||
| 4462.08 = 4479.08 - (3.09x5.5) | v2.2024.07 (model used for 2024 season) |
Plots by Season and by Week of Season
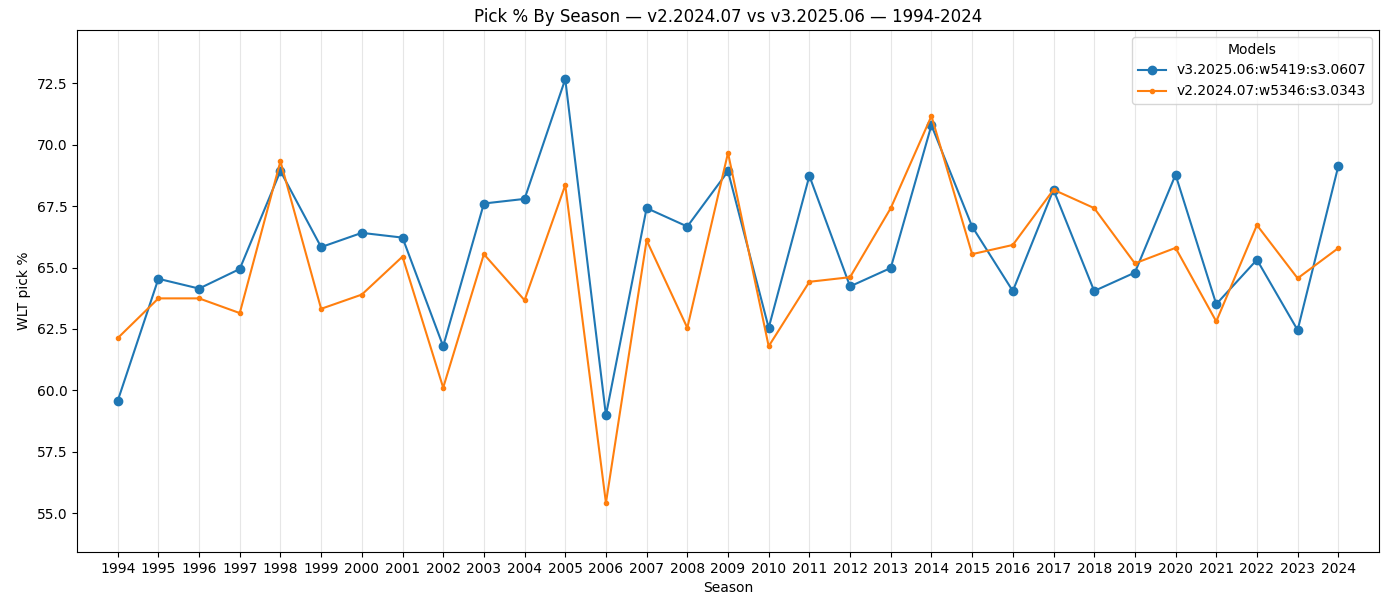
When looking by season, we see the newer v3.2025.06 model is consistently more accurate than the v2.2024.07 model
in seasons from 1995-2011, which is expected because last year's model wasn't evaluated against those seasons. There is
less of a consistent pattern in more recent seasons, and the newer model just happens to have been much more accurate
for the 2024 season. Again, the 2024 season wasn't weighted more heavily than any other season from 2004 onwards.
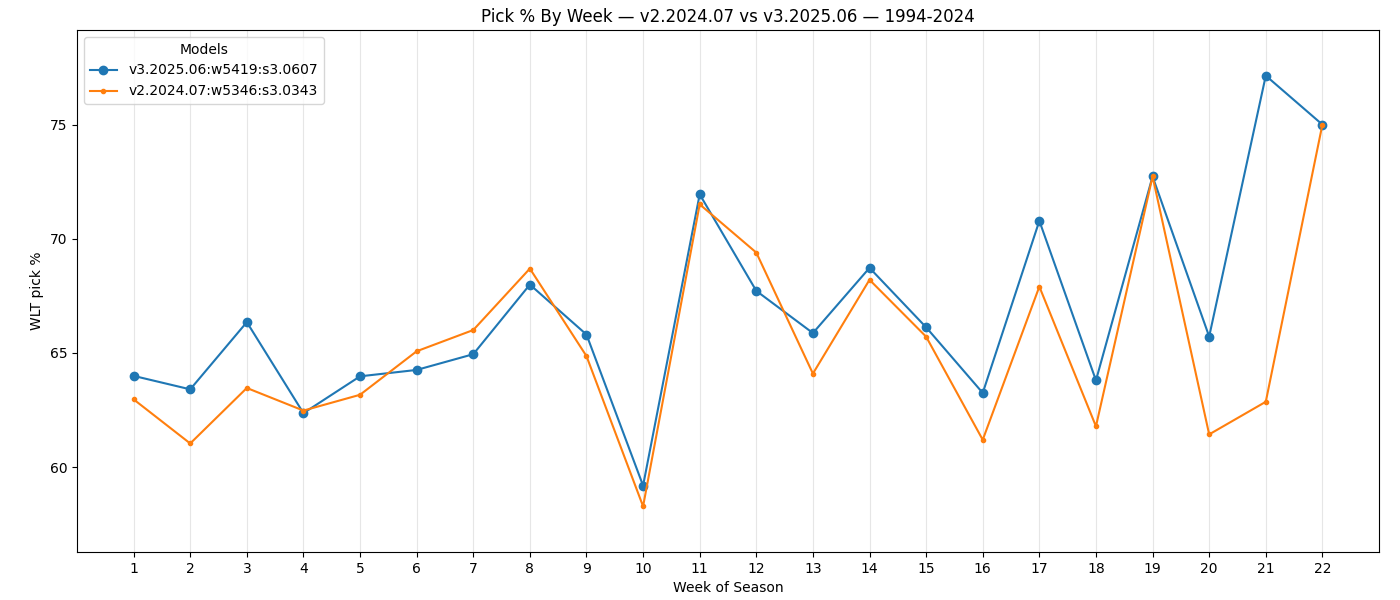
By week of season, we see the newer v3.2025.06 model is consistently better, and especially by the end of the season
and into the playoffs, which seems to be a good sign. The newer model is significantly better in weeks 20, 21, and 22,
which, depending on the season, were conference championship or Super Bowl weeks. It's worth noting here that all weeks
are treated the same when evaluating models, so for example playoff games are not weighted more heavily than regular season
games. It's also interesting that week 10 continues to be an unpredictable week even for the newest model.
This year's new 2025 blank slate model is consistently better than last year's, both by season:
![]()
and by week:
![]()
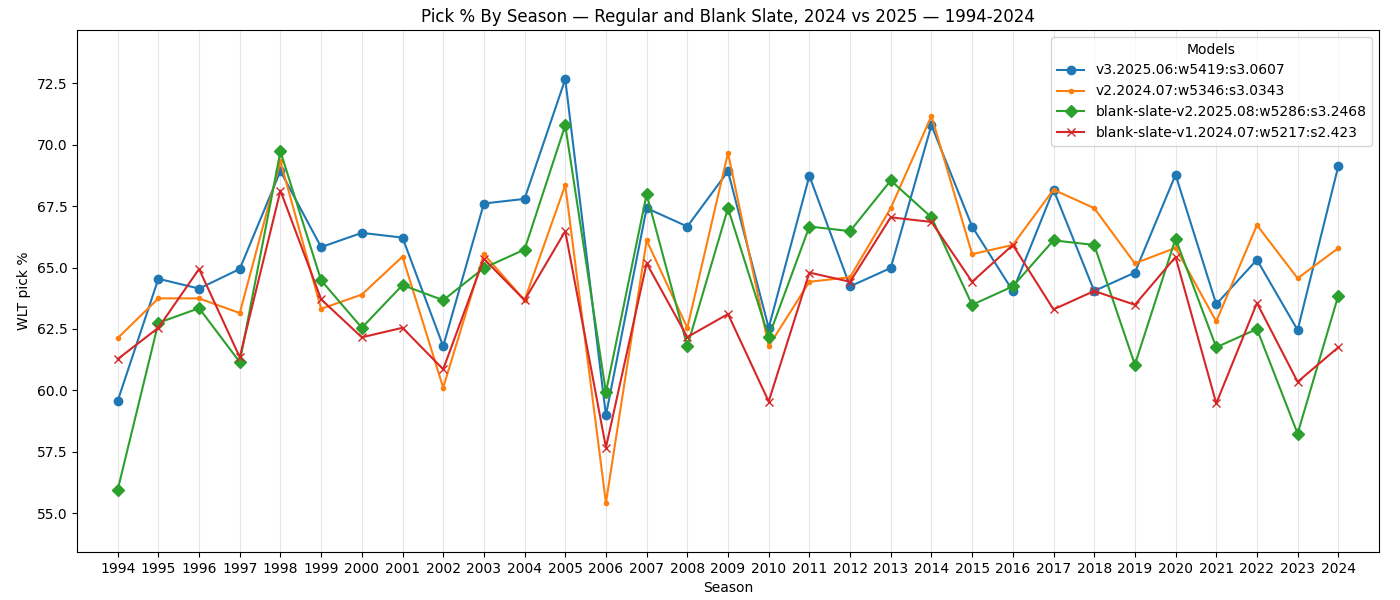
When we put both the regular and blank slate models on the same plot, we see this year's new blank slate model is better than last year's main model in 9 seasons from 1994-2011. Again, this is somewhat expected because last year's models were selected without taking those older seasons into consideration. It's also fun to see that the new blank slate model was the best in 6 of the last 31 seasons, the last being the 2013 season.
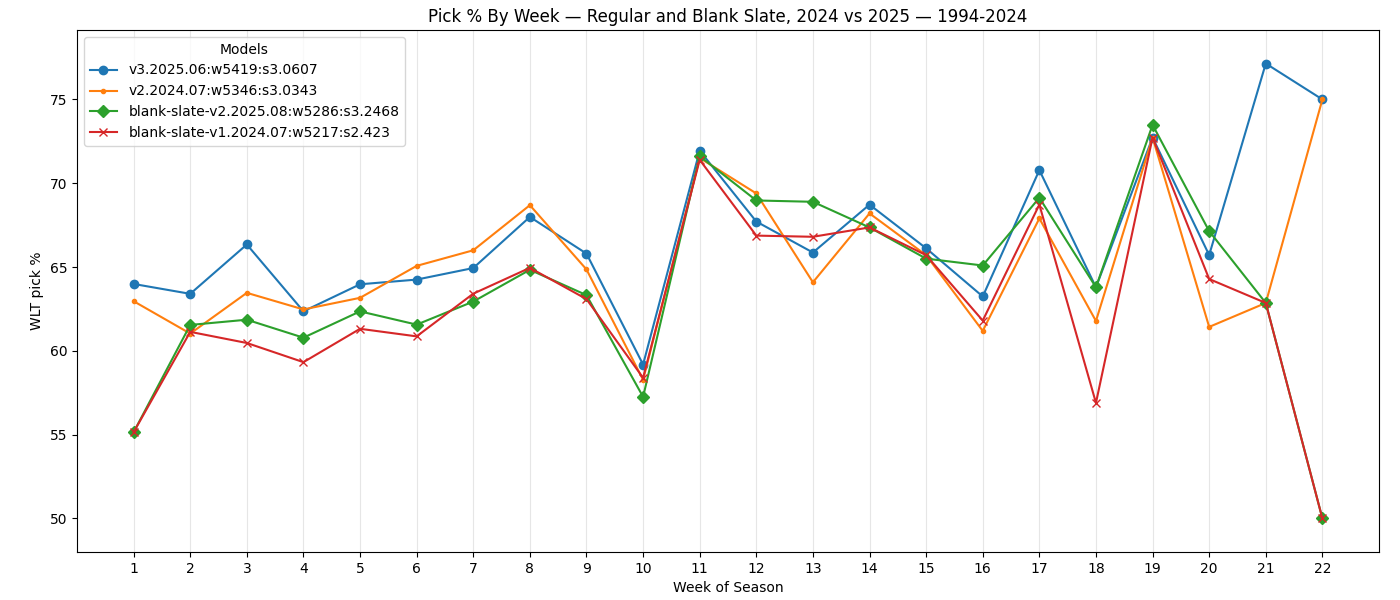
When all models are compared by week, we see the blank slate models are worse at the beginning of the season, as expected. Week 10 is still a strange weak point.
2025 Model and Season Page Improvements
Aside from the offseason model updates, there have been no changes or features added to the NFL Elo rating pages themselves.
I'll update this section as any changes are made during the season, either to the pages to the models.
Reverting the Model in Early January 2026
I've been thinking about this for the last few weeks, and I've decided to revert to last year's model for the rest of this season (between weeks 17 and 18). This doesn't cause dramatic changes in the rankings (see details below), and doesn't decrease the number of correctly-picked games this season, but does roll back the strange behavior exhibited by the model toward the end of the regular season: the expected margin of victory (for many games) was too large.
This was caused by giving my automated model search a parameter search space that was too wide. I expected any found misbehaving models like this to simply be less accurate and dropped, but instead the model search found many models with this behavior that pick more games correctly than last year's model.
When the expected margin of victory is too large near the end of the regular season and into the playoffs, we see strong teams lose Elo rating points even after good performances against weaker teams. I have a few theories about why this behavior doesn't ruin Elo model accuracy for the NFL:
- Playoff teams are often moved closer to each other in Elo, which:
- may reflect the increased parity we see in the postseason, but also
- in effect gives more weight to having a home game in the playoffs.
- By often lowering the Elo of teams that win in the wildcard round, we in effect give a decent Elo advantage to the teams that have a wildcard bye.
- If a favored team really blows out their opponent toward the end of the season, neither team's Elo rating will change much.
- Teams that finished the season strong and lost as underdogs (but were not blown out) in the playoffs, like the Broncos, Chargers, and Rams last year, get an Elo boost to start the following season.
Ultimately though, it seems like the model shouldn't behave like this. Losing Elo after a good performance clearly goes against the spirit of Elo ratings. Regardless of why/how these types of models end up being more accurate, I don't want to use a model with this behavior without reviewing lots of game outcomes to see if it actually is defensible and more accurate in most cases.
In the meantime, switching back to last year's model doesn't cause a big upheaval in the rankings. Most teams don't move much in the rankings with the change -- ten teams moved more than one spot for the week 17 rankings:
- Lions down 6 spots to #11
- Commanders down 4 spots to #27
- Patriots up 3 spots to #7
- Saints up 3 spots to #24
- Bills up 2 spots to #4
- Jaguars up 2 spots to #6
- 49ers up 2 spots to #10
- Dolphins up 2 spots to #23
- Broncos down 2 spots to #9
- Falcons down 2 spots to #21
The main 2025 page is now showing ratings and rankings using last year's v2.2024.07 model, and the 2025 v3.2025.06 model page is now available here